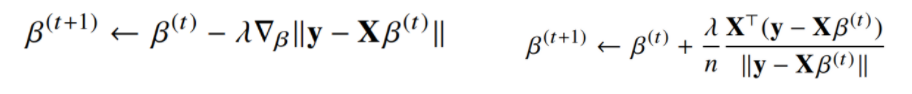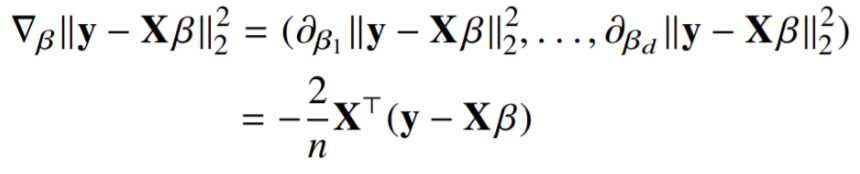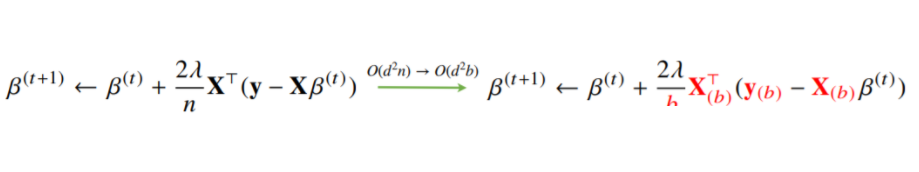$\Vert y-X\beta \Vert_2$가 아닌 $\Vert y-X\beta \Vert_2^2$를 최소화해도 된다
RMSE (Root Mean Squared Error)
벡터의 거리는 L2-norm으로 계산
Squared Error는 각 데이터별로 정답과 예측 벡터 사이를 L2-norm의 제곱으로 계산
Mean Squared Error는 Squared Error를 데이터 숫자만큼 나눠준다
Root Mean Squared Error는 MSE에 제곱근을 취해준다
RMSE는 L2-norm 정의와 유사하지만, 데이터 개수만큼 나눠줘야 한다!
정확히 쓰면 $E[\Vert y-X \beta \Vert]_2$로 써야한다 (기대값)
관용적으로 RMSE를 L2-norm처럼 쓴다
경사하강법으로 선형회귀 계수 구하기
계수 $\beta$에 대해 미분한 결과 → $X^T$
목적식을 최소화하는 $\beta$를 구하는 경사하강법 알고리즘
$\lambda$는 학습률
$\beta^{(t)}$는 t번째 단계에서의 coefficient
$\Vert y - X\beta \Vert_2$ 대신 $\Vert y - X\beta \Vert_2^2$을 최소화하면 식이 좀 더 간단해진다
계산이 더 쉽다
최적화 방향 같다, $L2$ 최적화와 $L2 ^2$ 최적화 같다.
경사하강법 기반 선형회귀 알고리즘
$\nabla_\beta \Vert y - X\beta \Vert_2^2$ 항을 계산해서 $\beta$ 업데이트
L2-norm은 $\sqrt{|x|^2 + |y|^2}$
Input: X, y, lr, T, Output: data
# norm: L2-norm 계산 함수
# lr: 학습률, T: 학습횟수
# 종료조건 - 일정 학습횟수로 변경
for t in range(T):
error = y - X @ beta
grad = - transpose(X) @ error
beta = beta - lr * grad
X = np.array([[1, 1], [1, 2], [2, 2], [2, 3]])
y = np.dot(X, np.array([1, 2])) + 3
beta_gd = [10.1, 15.1, -6.5] # [1, 2, 3]이 정답
X_ = np.array([np.append(x, [1]) for x in X]) # intercept 항 추가
for t in range(5000):
error = y - X_ @ beta_gd
# error = error / np.linalg.norm(error)
grad = - np.transpose(X_) @ error
beta_gd = beta_gd - 0.01 * grad
print(beta_gd) # [1.00000367 1.99999949 2.99999516]
경사하강법 알고리즘에선 학습률과 학습횟수가 중요한 hyperparameter가 된다
학습률 작으면 수렴 느리고, 크면 불안정한 움직임
학습횟수 작으면 경사하강법 수렴 잘 안될 수 있다
경사하강법은 만능일까?
이론적으로 경사하강법은 미분가능하고 볼록(convex)한 함수에 대해선 적절한 학습률과 학습횟수를 선택했을 때 수렴이 보장
볼록한 함수는 gradient vector가 항상 최소점을 향한다
[참고] 볼록함수 convex, 오목함수 concave
특히 선형회귀 경우 목적식 $\Vert y-X\beta \Vert_2$은 회귀계수 $\beta$에 대해 볼록함수이기 때문에 알고리즘을 충분히 돌리면 수렴이 보장된다
L2-norm
비선형회귀 문제의 경우 목적식이 볼록하지 않을 수 있으므로 수렴이 항상 보장되지는 않는다
딥러닝을 사용하는 경우 목적식은 대부분 볼록함수가 아니다 (non-convex)
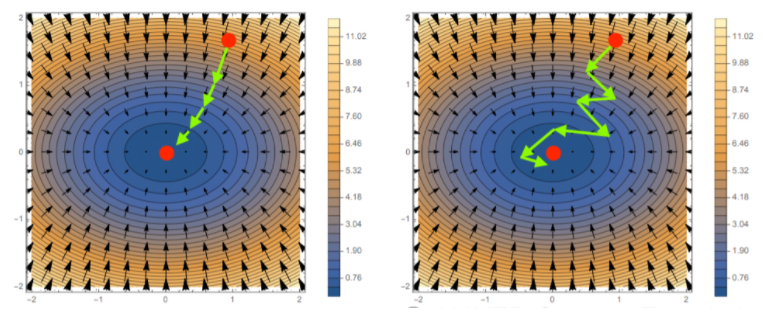
Stochastic Gradient Descent
확률적 경사하강법은 모든 데이터를 사용해서 업데이트하는 대신 데이터 한개 또는 일부(mini-batch) 활용하여 업데이트
볼록이 아닌(non-convex) 목적식은 SGD를 통해 최적화할 수 있다$\mathbb{E} [\widehat{\nabla_\theta \mathcal{L}}] \approx \nabla_\theta \mathcal{L}$