 [02] 행렬
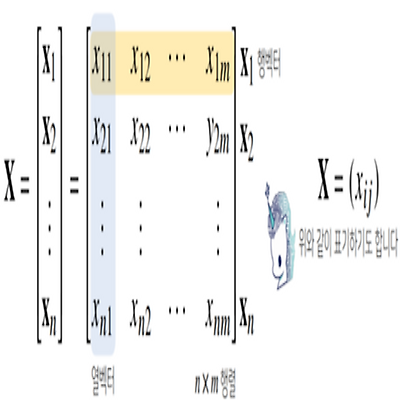
행렬이란? 행렬(matrix)는 벡터를 원소로 가지는 2차원 배열 벡터의 확장 벡터의 원소 → 숫자, 행렬의 원소 → 벡터 numpy에서는 행(row)이 기본 단위 x = np.array([1, -2, 3], [7, 5, 0], [-2, -1, 2]) 벡터 : 소문자 bold, 행렬 : 대문자 bold 행렬은 행(row)과 열(column)이라는 index를 가진다 $X = (x_{ij})$와 같이 표기하기도 한다 행렬의 특정 행(열)을 고정하면 행(열)벡터라고 부른다 전치행렬 (transpose matrix)은 행과 열의 인덱스가 바뀐 행렬 $X^T = (x_{ji})$ 행렬의 이해 (1) 벡터가 공간에서 한 점을 의미하면, 행렬은 여러 점들을 나타낸다 행렬의 행벡터 $x_i$는 i번째 데이터를 의미한..
[02] 행렬
행렬이란? 행렬(matrix)는 벡터를 원소로 가지는 2차원 배열 벡터의 확장 벡터의 원소 → 숫자, 행렬의 원소 → 벡터 numpy에서는 행(row)이 기본 단위 x = np.array([1, -2, 3], [7, 5, 0], [-2, -1, 2]) 벡터 : 소문자 bold, 행렬 : 대문자 bold 행렬은 행(row)과 열(column)이라는 index를 가진다 $X = (x_{ij})$와 같이 표기하기도 한다 행렬의 특정 행(열)을 고정하면 행(열)벡터라고 부른다 전치행렬 (transpose matrix)은 행과 열의 인덱스가 바뀐 행렬 $X^T = (x_{ji})$ 행렬의 이해 (1) 벡터가 공간에서 한 점을 의미하면, 행렬은 여러 점들을 나타낸다 행렬의 행벡터 $x_i$는 i번째 데이터를 의미한..






