모델 저장하고 불러오기
model.save()
- 학습의 결과를 저장하기 위한 함수
- 모델 형태(architecture)와 파라메터를 저장
- 모델 학습 중간 과정의 저장을 통해 최선의 결과모델을 선택
- 만들어진 모델을 외부 연구자와 공유하여 학습 재연성 향상
# 모델 저장 폴더 만들기
MODEL_PATH ="saved"
if not os.path.exists(MODEL_PATH):
os.makedirs(MODEL_PATH)
# 모델 파라미터만 저장
torch.save(model.state_dict(), os.path.join(MODEL_PATH, "model.pt"))
# 같은 모델 형태에서 파라미터만 load
new_model = TheModelClass()
new_model.load_state_dict(torch.load(os.path.join(MODEL_PATH, "model.pt")))
# 모델의 구조까지 저장
torch.save(model, os.path.join(MODEL_PATH, "model.pt"))
# 모델 load
model = torch.load(os.path.join(MODEL_PATH, "model.pt"))torchsummary 사용하기
- 아래 출력화면 처럼 모델 전체적인 구조와 Input output shape 확인 가능 !
- 모델을 불러와서 사용할 때 구조 확인하고 커스텀 할 때 좋을 듯
from torchsummary import summary
summary(model, (3, 224, 224))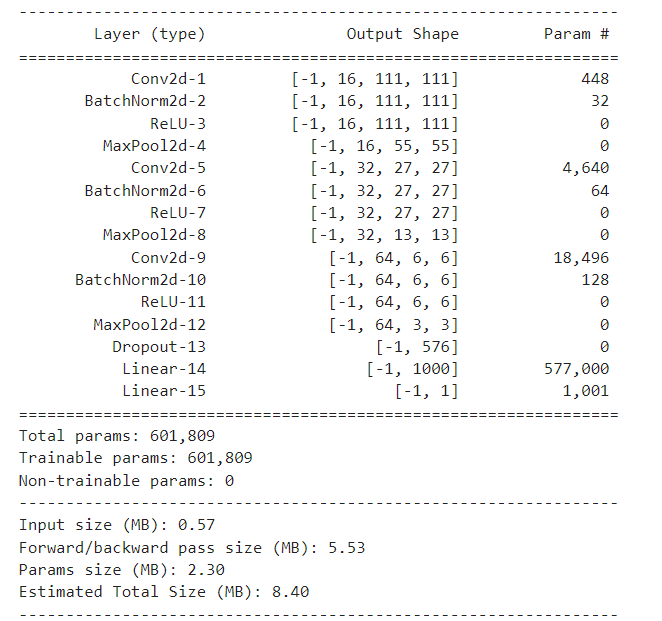
pretrained model
torchvision.models 에서 많은 pretrained model을 제공한다.
import torchvision.models as models
resnet18 = models.resnet18(pretrained=True)
alexnet = models.alexnet(pretrained=True)
squeezenet = models.squeezenet1_0(pretrained=True)
vgg16 = models.vgg16(pretrained=True)
densenet = models.densenet161(pretrained=True)
inception = models.inception_v3(pretrained=True)
googlenet = models.googlenet(pretrained=True)
shufflenet = models.shufflenet_v2_x1_0(pretrained=True)
mobilenet_v2 = models.mobilenet_v2(pretrained=True)
mobilenet_v3_large = models.mobilenet_v3_large(pretrained=True)
mobilenet_v3_small = models.mobilenet_v3_small(pretrained=True)
resnext50_32x4d = models.resnext50_32x4d(pretrained=True)
wide_resnet50_2 = models.wide_resnet50_2(pretrained=True)
mnasnet = models.mnasnet1_0(pretrained=True)
efficientnet_b0 = models.efficientnet_b0(pretrained=True)
efficientnet_b1 = models.efficientnet_b1(pretrained=True)
efficientnet_b2 = models.efficientnet_b2(pretrained=True)
efficientnet_b3 = models.efficientnet_b3(pretrained=True)
efficientnet_b4 = models.efficientnet_b4(pretrained=True)
efficientnet_b5 = models.efficientnet_b5(pretrained=True)
efficientnet_b6 = models.efficientnet_b6(pretrained=True)
efficientnet_b7 = models.efficientnet_b7(pretrained=True)
regnet_y_400mf = models.regnet_y_400mf(pretrained=True)
regnet_y_800mf = models.regnet_y_800mf(pretrained=True)
regnet_y_1_6gf = models.regnet_y_1_6gf(pretrained=True)
regnet_y_3_2gf = models.regnet_y_3_2gf(pretrained=True)
regnet_y_8gf = models.regnet_y_8gf(pretrained=True)
regnet_y_16gf = models.regnet_y_16gf(pretrained=True)
regnet_y_32gf = models.regnet_y_32gf(pretrained=True)
regnet_x_400mf = models.regnet_x_400mf(pretrained=True)
regnet_x_800mf = models.regnet_x_800mf(pretrained=True)
regnet_x_1_6gf = models.regnet_x_1_6gf(pretrained=True)
regnet_x_3_2gf = models.regnet_x_3_2gf(pretrained=True)
regnet_x_8gf = models.regnet_x_8gf(pretrained=True)
regnet_x_16gf = models.regnet_x_16gf(pretrainedTrue)
regnet_x_32gf = models.regnet_x_32gf(pretrained=True)
NLP 분야 pretrained model 은 HuggingFace 사용
Models - Hugging Face
Hardware Scale with dedicated hardware
huggingface.co
Freezing
pretrained model 활용시 모델의 일부분은 frozen 시키기 원할 때
parameter의 requires_grad을 False 해줌으로서 가능
vgg = models.vgg16(pretrained=True).to(device)
class MyNewNet(nn.Module):
def __init__(self):
super(MyNewNet, self).__init__()
self.vgg19 = models.vgg19(pretrained=True)
self.linear_layers = nn.Linear(1000, 1)
# Defining the forward pass
def forward(self, x):
x = self.vgg19(x)
return self.linear_layers(x)
for param in my_model.parameters():
param.requires_grad = False
for param in my_model.linear_layers.parameters():
param.requires_grad = True'부스트캠프 AI Tech > Pytorch' 카테고리의 다른 글
| [14] monitoring tool - wandb (0) | 2022.01.24 |
|---|---|
| [13] Monitoring tool - Tensorboard (0) | 2022.01.24 |
| [11] image transform (1) | 2022.01.23 |
| [10] Dataloader 의 기본요소 (0) | 2022.01.22 |
| [09] Dataset (0) | 2022.01.21 |


