- 글자 검출 객체 특징
- 매우 높은 밀도
- 극단적 종횡비
- 모호한 객체 영역
- 크기 편차
- 글자 영역 표현법
- 직사각형 (x1, y1, x2, y2) or (x1, y1, w, h) or + 각도
- 사격형 (x1, y1 ---, x4, y4) -> 시계방향으로
- 다각형 -> 상하 점들이 쌍을 이루도록 짝수 점으로 표현
- Regression-based vs Segmentation-based

- Regression-Based
- Arbitrary-shaped text -> 불필요한 영역을 포함 ( Bounding box 표현 방식의 한계 )
- Extreme aspect ratio -> Bounding box 정확도 하락 ( Receptive field 의 한계 )
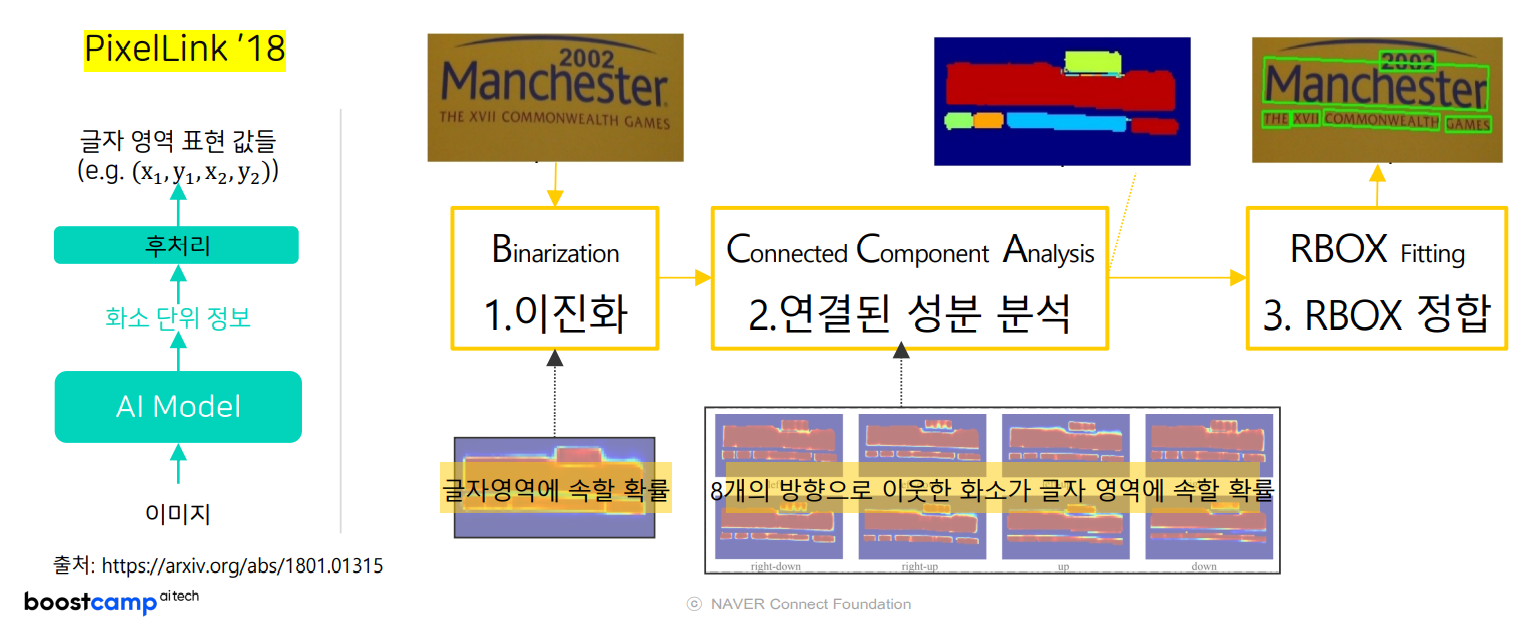
- Segmentation-Based
- 각 화소 별로 인접한 8개 화소가 글자 영역에 속하는 지 파악
- 복잡하고 시간이 오래 걸리는 post-processing이 필요할 수 있음
- 서로 간섭이 있거나 인접한 개체 간의 구분이 어려움
- 그래서 Hybrid로 Regression-based로 대략의 사각영역 추출 후 화소 정보 추출
- Character-based vs Word-based
- Word-based methods 를 선호 ( labeling 비용, 시간 등 때문 )
- Baseline Model - EAST ( Efficient and Accurate Scene Text Detector. CVPR, 2017)
EAST: an efficient and accurate scene text detector (CVPR 2017)
논문 제목: EAST: An Efficient and Accurate Scene Text Detector 연구 기관: Megvii Word box detection 의 정확성을 높이는 기술에 촛점을 맞춘 연구 논문이다 (인식 기술 자체는 본...
kaiertech.blogspot.com
'부스트캠프 AI Tech > 데이터 제작' 카테고리의 다른 글
| [6] Annotation Guide (0) | 2021.11.16 |
|---|---|
| [5] 데이터 소개 (0) | 2021.11.16 |
| [3] OCR Technology and Services (0) | 2021.11.15 |
| [2] 데이터 제작의 중요성 Ⅱ (0) | 2021.11.15 |
| [1] 데이터 제작의 중요성 Ⅰ (0) | 2021.11.15 |



