부스트캠프 AI Tech/모델 최적화
[01] 모델 경량화 개요
태호님
2021. 11. 24. 17:09
- 경량화의 목적
- On device AI
- Power usage
- RAM Memory usage
- Storage
- Computing power
- AI on cloud
- Latency ( 요청 처리 시간)
- Throughput ( 단위 시간 당 처리 가능 요청 수 )
- 경량화, 최적화 종류
- 네트워크 구조 관점
- Efficient Architecture Design(+AutoML; Nerual Architecture Search(NAS))
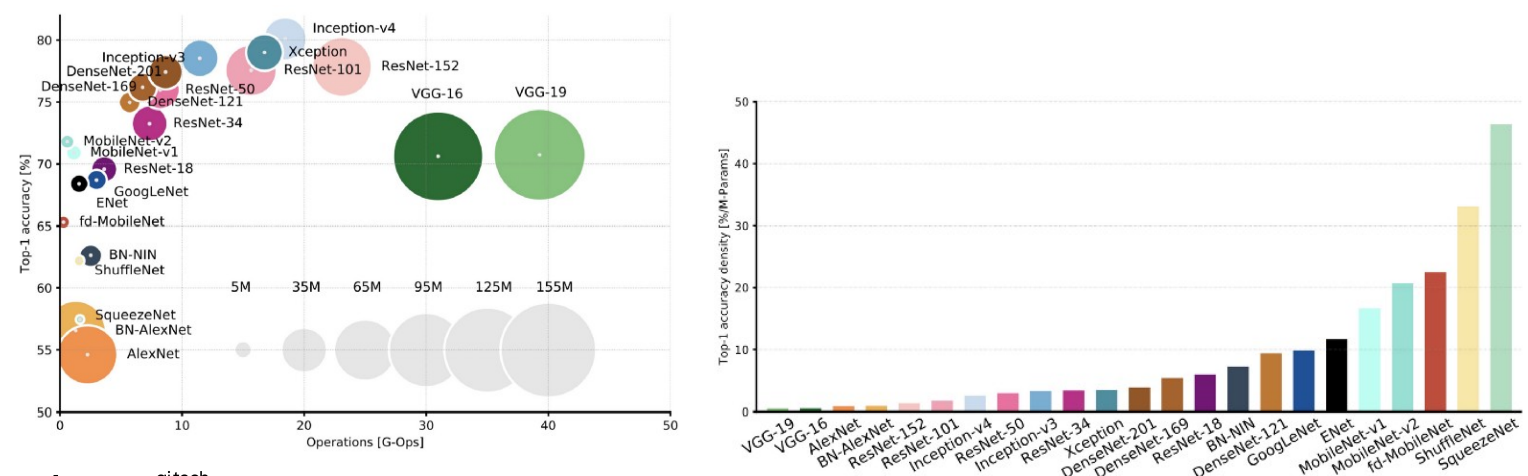
- Network Pruning : 찾은 모델 줄이기 ( 일반화하여 적용하기 아직 까진 어렵다 )
- 중요도가 낮은 파라미터를 제거하는 것
- 좋은 중요도 ? -> loss gradient크면 등등
- Structured Pruning : 파라미터를 그룹 단위 ( channel / filter, layer 등)
- Unstructured Pruning : 파라미터 각각을 독립적으로 pruning
- Knowledge distillation ( 일반화하여 적용하기 아직 까진 어렵다 )
- 학습된 큰 네트워크를 작은 네트워크의 학습 보조로 사용
- Student network 와 ground truth label의 cross-entropy
- teacher network 와 strudent network의 inference 결과에 대한 KLD loss
- Matrix / Tensor decomposition ( -> 수학적으론 복잡하나, 간단한 구현으로 좋은 효과 )
- 하나의 Tensor를 작은 tensor들의 operation들의 조합으로 표현 하는 것
- Hardware 관점 ( -> 성능에 가장 큰 영향을 주는 요소 )
- Network Quantization
- 일반적인 float32 데이터 타입의 연산과정을 float16, int8.. 으로 변환하여 연산 수행
- Quantization error 발생하여 일반적으로 성능 하락 but 사이즈 감소, 속도 향상
- Network Compiling
- 학습이 완료된 Network를 deploy 하려는 target hardware에서 inference가 가능하도록 compile 하는 것
- 사실상 속도에 가장 큰 영향을 미침
- TensorRT(NVIDIA), Tflite(Tensorflow), TVM(apache) ...
- Compile 과정에서 layer fusion(graph optimization) 등의 최적화가 수행됨
- AutoML로 graph의 좋은 fusion을 찾아내자 ( AutoTVM ..)
'부스트캠프 AI Tech/모델 최적화' Related Articles

